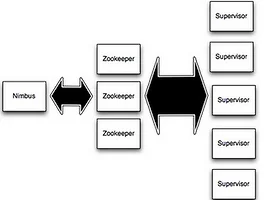
IT for developer (56) 썸네일형 리스트형 [스톰] Storm Tutorial 원문 : https://github.com/nathanmarz/storm/wiki/TutorialTutorial이 튜토리얼에서, 어떻게 스톰 토폴로지를 생성하고 스톰 클러스에 그것들을 배치하는지 배울 것이다. 자바가 사용될 주요 언어가 되겠지만 몇몇 예제는 스톰의 다중 언어 능력을 보이기 위하여 파이썬을 사용할 것이다. Preliminaries이 튜토리얼은 storm-starter 프로젝트의 예제를 사용한다. 프로젝트를 복제해서 해당 예제를 따라하길 추천한다. 다음을 읽고 설정하자. Setting up development environment (https://github.com/nathanmarz/storm/wiki/Setting-up-development-environment) 와 Creating a.. HBase - DELETE HTable에 다음 함수를 통해 삭제를 수행한다. void delete (Delete delete) throws IOException put과 유사하게 Delete 객체를 생성해서서 전달하면 된다. Delete 객체를 생성하는 방법도 기존 Get, Put 객체를 생성하는 것과 유사하다. Delete(byte[] row) Delete(byte[] row, long timestamp, RowLock rowLock) 특정 컬럼 패밀리 또는 컬럼을 지정하여 삭제할 수도 있다. 아무것도 지정하지 않으면 해당 rowKey에 해당하는 모든 셸을 지운다. Delete deleteFamily(byte[] family) Delete deleteFamily(byte[] family, long timestamp) Delete.. BLENDING TIME IN HBASE 원문: http://outerthought.org/blog/417-ot.html HBase에 타임스탬프에 관한 글이다. 발번역~ 차라리 구글번역이 낫겠지만. 개인적으로 공부한다고 생각으로 발번역중 BigTable 과 같은 HBase는 흔치않고, 분산, 영구적인 다차원 정렬맵이다. (흠냐.) 이 맵은 row 키, 컬럼 키 그리고 타입 스탬프로 색인되어 있고 맵안에 각 값은 바이트의 배열로 되어있다. 좀 더 자세히 보면, Hbase에는 테이블과 컬럼 패밀리라는 또 다른 차원을 가지고 있다. 그 차원들은 모두 동일하지 않다. 예를 들어, row 차원은 조각날 수 있고 매우 커질수 있다. 컬럼은 조각되지 않지만 row들과 비교하여 하나의 row 안에 다중 컬럼이 원자적으로 put 또는 delete 될수 있다. .. HBase - PUT HBase: The Definitive Guide 일부 발번역 HTable에 write하기 위해서는 Put 객체를 생성하고 put 함수를 호출하면된다. 하나 row를 Put 하기 void put(Put put) throws IOException Put(byte[] row) Put(byte[] row, RowLock rowLock) Put(byte[] row, long ts) Put(byte[] row, long ts, RowLock rowLock) 예) Configuration conf = HBaseConfiguration.create(); HTable table = new HTable(conf, "testtable"); Put put = new Put (Bytes.toBytes("row1")); put.. HBase - GET HBase: The Definitive Guide 일부 발변역~ GET 메소드 (필터에 대해서는 다른 챕터에 나와있는듯 ) HTable은 저장된 것을 가져오기 위한 API로 GET 과 매칭 클래스들을 제공하고있다. 단일 row를 가져오기 위한 함수 Result get(Get get) throws IOException Get (byte[] row) Get (byte[] row, RowLock rowLock) 예) byte[] row1 = Bytes.toBytes("row1"); //'row1'은 해당 row의 키 Get get1 = new Get(row1); Result[] results = table.get(get1); get 오퍼레이션은 특정 row 하나만을 가져오지만 거기에 포함되어 있는 수많은 컬럼.. Cloudera Hadoop 설치시 Missing Dependency: JDK 오류 발생 hadoop-0.20-0.20.2+923.21-1.noarch from cloudera-cdh3 has depsolving problems --> Missing Dependency: jdk >= 1.6 is needed by package hadoop-0.20-0.20.2+923.21-1.noarch (cloudera-cdh3) Error: Missing Dependency: jdk >= 1.6 is needed by package hadoop-0.20-0.20.2+923.21-1.noarch (cloudera-cdh3) JDK RPM 버전을 Sun에서 받아서 설치하자. yum install java로 설치하면 rpm dependency를 제대로 구분 못하는 듯하다. Performance Tuning Hbase HBase: The Definitive Guide 책에서 발번역 -early edition 번역 1. 가비지 컬렉션 region server인 경우 가비지 컬렉션 파라미터를 조정할 필요가 있다. 마스터인 경우 많은 로드가 발생하지 않으므로 다음의 셋팅들은 region server들에게만 필요하다. HBase를 효과적으로 수행하는데 왜 가비지 컬렉션을 할까? 이 문제는 JRE가 프로그램이 무엇을 하는지, 어떻게 객체를 생성하는지 등에 관한 추정에 관여하는 것으로 부터 발생된다. 이 가정들은 대부분의 경우 잘 동작한다. 그리고 JRE는 프로세스가 동작하고 이을 때 이런 추정들을 조정하는 휴리스틱 알고리즘을 가지고 있다. 그러나 region 서버와 같은 경우 잘 다루지 못한다. 이는 작업량, 특히 JRE 추정.. Tuning for performance in hadoop Hadoop in Action 1. combiner를 가지고 네트워크 트래픽 줄이기 2. 입력 데이터 양을 줄이기 3. 압축 사용하기 4. JVM 재사용 디폴트로, TaskTracker는 Mapper와 Reducer를 분리된 JVM 으로 수행한다. 태스크 시작 비용이 상당히 클 수 있으며 이를 해결하기 위해서 job.reuse.jvm.num.tasks 1보다 큰값 또는 -1 (no limit) 5. speculative execution 을 가지고 실행하기. map 또는 reduce task가 실행중 오류가 발생한 경우 또는 너무 느린 경우 새로운 태스크를 수행하고 기존 태스크를 kill한다. 기본 설정이 이렇게 동작하도록 되어 있으며 이를 수정하기 위해서 다음 속성들을 FALSE로 지정한다. mapre.. 이전 1 2 3 4 5 6 7 다음