Guaranteeing message processing
원문:https://github.com/nathanmarz/storm/wiki/Guaranteeing-message-processing
그동안 너무 바뻐서 올만에 발번역~
스톰은 Spout 서 나온 각 메세지들이 완전히 처리되는 것을 보장한다. 이 페이지는 어떻게 스톰이 이를 보장하고 있는지, 스톰의 신뢰성을 이용하기 위해 무엇을 해야하는지 기술한다. (아직까지 Spout를 어떻게 우리말로 바꿀지 모르겠다;;)
What does it mean for a message to be "fully processed"?
(메세지가 완전히 처리되었다는 의미가 무엇인가?)
Spout에서 나온 튜플은 이를 기반으로 만들어진 수많은 튜플들을 트리거할수 있다. 예를들어 스트리밍 워드 카운트 토폴로지 살펴보자.
TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("sentences", new KestrelSpout("kestrel.backtype.com", 22133, "sentence_queue", new StringScheme())); builder.setBolt("split", new SplitSentence(), 10) .shuffleGrouping("sentences"); builder.setBolt("count", new WordCount(), 20) .fieldsGrouping("split", new Fields("word"));
이 토폴로지는 Kestrel 큐로 부터 문장들을 읽고 문장을 단어들로 쪼갠다. 그리고 각 단어마다 해당 단어가 몇번 나왔는지를 알려주는 숫자를 내보낸다. Spout에서 나온 하나의 튜플은 이 튜플에 기반해서 만들어진 여러 튜플들을 트리거한다. (문장안에 각 워드에 대한 튜플들과 각 워드의 카운트를 업데이트하기 위한 튜플들) 이는 다음과 같이 세가지 메시지 트리로 표현될 수 있다.
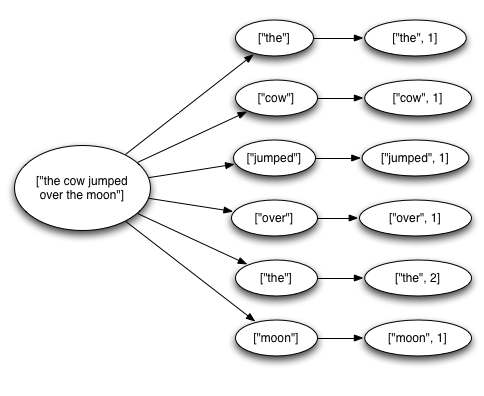
스톰은 튜플 트리가 완전히 소모되고 트리에 모든 메세지가 처리됐었을 때 Spout으로 부터 나온 튜플이 완전히 처리됐다고 간주한다. 메세지 트리가 지정된 타임아웃안에 완전히 처리되는 것이 실패하면 해당 튜플은 실패한 것으로 간주한다. 타임아웃은 Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS 설정으로 지정할 수 있으며 디폴트 값은 30초이다.
What happens if a message is fully processed or fails to be fully processed?
(메세지가 완전히 처리되거나 완전히 처리되는 것을 실패하면 어떤일이 벌어지나?)
해당 질문을 이해하기 위해, Spout로 부터 나온 튜플의 라이프사이클을 살펴보자. Spout 구현하고 있는 인터페이스를 살펴보면 다음과 같다. 좀 더 자세한 내용은 javadoc 에서
public interface ISpout extends Serializable { void open(Map conf, TopologyContext context, SpoutOutputCollector collector); void close(); void nextTuple(); void ack(Object msgId); void fail(Object msgId); }
우선, 스톰은 nextTuple 메소드를 호출하여 Spout로 부터 튜플을 요청한다. Spout는 출력 스트림에 튜플을 내보내기 위하여 open 메소드에서 제공되는 SpoutOutputCollector를 사용한다. 튜플이 내보내지면 Spout는 추후에 튜플을 식별하기 위해 사용되는 메세지 ID를 제공한다. 예를 들어, KestrelSpout은 kestrel 큐에서 메세지를 읽고 메세지를 위해 Kestrel에 의해 만들어진 메세지 ID를 가지고 내보내진다. SpoutOutputCollector에 메세지를 내보내는 코드는 다음과 같다.
_collector.emit(new Values("field1", "field2", 3) , msgId);
그 다음, 해당 튜플은 Bolt에 보내지고 스톰은 생성된 메세지들의 트리를 추적한다. 만약에 튜플이 완전히 처리된 것을 알아차리면 스톰은 Spout가 스톰에게 전달한 메세지 ID를 가지고 Spout 태스크의 ack 함수를 호출할 것이다. 그와 비슷하게 타임아웃이 발생하면 스톰은 Spout에 fail 함수를 호출할 것이다. 튜플은 자신을 생성한 Spout 태스크에 의해 ack되거나 fail 될 것이다. 만약 Spout이 클러스터에 걸쳐 여러 태스크로 실행되고 있다면 해당 튜플을 생성한 태스크에 의해서만 ack되거나 fail될 것이다. (Storm --> Spout --> Tuple)
메세지 처리를 보장하기 위하여 Spout가 무엇이 필요한지 살펴보기 위해 KestrelSpout를 다시 사용하자. KestrelSpout이 Kestrel 큐로 부터 메세지를 꺼내면 "open" 이 호출된다. 이는 아직 큐에서 실제적으로 제거되지 않았음을 의미하고 메세지가 완전히 처리됐다는 확인메세지를 기다리고 있는 "pending" 상태에 놓인다. 그리고 만약에 클라이언트가 모든 pending 메세지들과 연결을 끊으면 큐로 다시 돌려보낸다. 메세지가 오픈되면 Kestrel 은 클라이언트에서 메세지를 위한 데이터 뿐만아니라 메세지의 유일한 ID 를 제공한다. KestrelSpout은 SpoutOutputCollector에게 튜플을 내보낼 때 메세지 ID로 해당 ID를 사용한다. 후에 KestrelSpout에 ack 또는 fail가 호출될 때, KestrelSpout은 큐에서 메세지를 제거하거나 다시 넣기 위하여 해당 메세지 ID를 가지고 Kestrel에게 ack 또는 fail 메세지를 보낸다.
What is Storm's reliability API?
(스톰의 신뢰성 API란 무엇인가?)
스톰의 신뢰 기능을 이용하기 위해서는 두 가지를 해야만 한다.
첫째, 스톰에게 튜플 트리에 새로운 링크를 생성할 때마다 알려줘야한다. (anchor)
둘째, 각 튜플을 처리하는 것이 끝나면 스톰에게 알려줘야한다. (ack or fail)
이 두 가지 일을 통해, 스톰은 튜플 트리가 완전히 처리됐는지 알아차리고 적절하게 Spout에게 ack 또는 fail을 할 수 있다. 스톰의 API는 간단한 방법으로 이 두 가지를 할 수 있도록 해준다.
public class SplitSentence extends BaseRichBolt { OutputCollector _collector; public void prepare(Map conf, TopologyContext context, OutputCollector collector) { _collector = collector; } public void execute(Tuple tuple) { String sentence = tuple.getString(0); for(String word: sentence.split(" ")) { _collector.emit(tuple, new Values(word)); } _collector.ack(tuple); } public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } }
각 워드 튜플은 emit 메소드의 첫번째 인수에 입력 튜플을 지정하여 앵커된다.(anchored). 워드 튜플이 앵커된 후 트리의 최상위에 Spout 튜플은 워드 튜플이 다운스트림에서 처리가 실패했다면 후에 리플레이할 것이다. 이와 다르게, 다음과 같이 워드 튜플을 내보내면 어떤일이 벌어지는지 살펴보자.
_collector.emit(new Values(word));
이 방법으로 워드 튜플을 내보내는 것은 앵커되지 않는다. 만약에 다운스트림 처리가 실패되면 최상위 튜플은 리플레이하지 않을 것이다. 토폴로지에 필요로 하는 장애 허용 보장정도에 따라 때때로 앵커되지 않는 튜플을 내보는 것이 적절할 수도 있다.
출력 튜플은 하나의 입력 튜플 이상에 앵커될 수 있다. (B,C --> D) 이는 조인 또는 군집 연산등을 수행할 때 유용하다. 처리시 실패한 다중 앵커된 튜플은 다중의 Spout로 부터 리플레이 되도록 한다. 다중 앵커는 단일 튜플보다 튜플들의 리스트를 지정하여 만들수 있다.
List<Tuple> anchors = new ArrayList<Tuple>(); anchors.add(tuple1); anchors.add(tuple2); _collector.emit(anchors, new Values(1, 2, 3));
다중 앵커는 다중 튜플 트리들에 출력 튜플을 추가한다. 트리형태가 아닌 DAG(Directed Acyclic Graph) 튜플을 생성할 수도 있다.
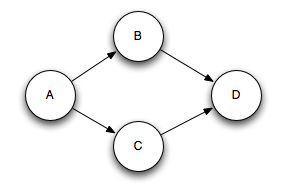
스톰은 트리뿐 아니라 DAG를 위해서도 잘 동작한다. (pre-release는 tree만 동작한다.)
앵커는 튜플 트리를 명시하는 방법이고 그 다음으로 스톰의 신뢰성 API에서 할 것은 튜플 트리에서 개별 튜플 처리를 끝나면 이를 명시하는 것이다. 이는 OutputCollector의 ack와 fail 함수를 사용하면 된다. SpitSentence 예제를 다시 살펴보면, 모든 워드 튜플이 나온 후에 입력 튜플이 ack되는 것을 볼 수 있다.
튜플 트리 최상위에서 spout 튜플을 즉시 실패한 것으로 하기 위해서 OutputCollector에 fail 메소드를 사용할 수 있다. 예를 들어 애플리케이션이 데이터베이스 클라이언트로 부터 예외를 처리하도록 하고 명시적으로 입력 튜플이 실패한 것으로 할 수 있다.(try catch에서 fail 함수를 호출한다.) 명시적으로 튜플을 실패로 하는 것은 Spout 튜플이 타임아웃이 될 때 까지 기다리는 것보다 더 빠르게 리플레이 될 수 있다.
처리되는 모든 튜플은 ack되거나 fail되어야만 한다. 스톰은 각 튜플을 추적하기 위하여 메모리를 사용하여 모든 튜플에 ack/fail을 하지 않으면 태스크는 결국 메모리가 꽉차버릴 것이다.
많은 Bolt들이 입력 튜플을 읽고 이에 기반하여 튜플을 내보내고, execute 메소드 끝에 튜플을 ack하는 일반적인 패턴을 따른다. 이러한 Bolt들은 필터들과 간단한 함수들로 이루어져 있다. IBasicBolt 인터페이스는 이러한 패턴을 추상화하고 있다. SplitSentence 예제에서 IBasicBolt가 다음과 같이 사용될 수 있다. (BaseBasicBolt는 IBasicBolt를 구현하고 기본 클래스)
public class SplitSentence extends BaseBasicBolt { public void execute(Tuple tuple, BasicOutputCollector collector) { String sentence = tuple.getString(0); for(String word: sentence.split(" ")) { collector.emit(new Values(word)); } } public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } }
이 방법은 이전에 구현한 방법보다 좀 더 간단하다. BasicOutputCollector 에 내보내지는 튜플들은 자동으로 입력 튜플에 앵커되고 입력 튜플은 execute 메소드가 완료되면 자동으로 ack된다.
반대로, 군집 또는 조인을 수행하는 Bolt들은 튜플들에 기반한 계산을 완료할 때 까지 튜플 ack를 연기할 것이다. 군집 과 조인은 출력 튜플들에 다중으로 앵커할 것이다. IBasicBolt 패턴에 포함되어 있지 않다.
How do I make my applications work correctly given that tuples can be replayed?
스톰 0.70.0, "transactional toplogies 특징에 의해 장애 내성을 수행할 수 있다. transactional topologies 에대한 자세한 내용은 여기
How does Storm implement reliability in an efficient way?
(어떻게 스톰이 효율적인 방법으로 신뢰성을 구현하고 있는가?)
스톰 토폴로지는 모든 Spout 튜플에 대해 튜플의 DAG를 추척하는 "acker" 태스크 집합을 가지고 있다. DAG가 완료됐음을 acker가 감지하면, 메세지를 ack하기 위해 Spout 튜플을 생성했던 Spout 태스크에게 메세지를 보낸다. 토폴로지당 acker 태스크의 수는 Config.TOPOLOGY_ACKERS 속성을 지정하면 된다. 디폴트는 1 태스크. 많은 메세지를 처리하는 토폴로지인 경우 이 수를 늘릴 필요가 있다.
스톰의 신뢰성에 대해 이해하는 최선의 방법은 튜플의 라이프사이클과 튜플 DAG를 살펴보는 것이다. 토폴로지에 튜플이 생성되면 (Spout이든 Bolt이든) , 이는 64비트 ID를 가진다. 이 ID들은 모든 Spout 튜플에 대해 DAG 튜플을 추적하기 위해 acker에 의해 사용된다.
모든 튜플은 튜플 트리안에 존재하는 Spout 튜플들의 ID를 알고 있다. Bolt 에 새로운 튜플을 내보낼 때 튜플 앵커의 Spout 튜플 ID들이 새로운 튜플에 복사된다. 튜플이 ack되면, 어떻게 튜플트리가 변경되었는지에 대한 정보를 적당한 acker 태스크에 보낸다. 특히, acker에게 다음과 같이 말한다. 튜플 왈:"이 Spout 튜플 처리는 지금 완료되었고 여기 나에게 앵커된 새로운 튜플들이 있다."
예를 들어, 다음 그림은 튜플 "D"와 "E"는 튜플 "C"에 기반해 생성되었다면 C"가 ack될때 튜플 트리는 어떻게 변화되는지 보여주고 있다.
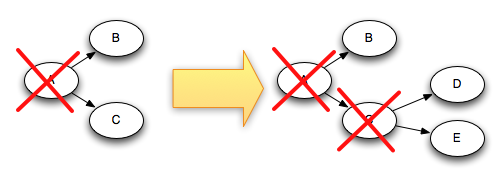
"D"와 E"가 추가됨과 동시에 트리에서 "C"가 제거 되기 때문에 트리는 결코 완료될 수 없다.
이제 스톰이 튜플 트리를 어떻게 추척하는지 상세히 볼 것이 있다. 이미 말한 것 처럼, 토폴로지에 acker의 수를 임의로 지정할 수 있다. 이는 다음과 같은 의문을 갖게 한다. 튜플이 토폴로지에서 ack될 때, 어떻게 어떤 acker에게 메세지를 전달해야할지 알수 있을까?
스톰은 Spout 튜플 ID와 acker 태스크와 매핑하기 위하여 mod 해싱을 사용한다. 모든 튜플은 자신에 속한 모든 트리에 Spout 튜플 ID를 가지고 움직이기 때문에 어떤 acker 태스크와 통신해야할지 알고 있다.
또 알아야할 것으로 스톰은 acker 태스크가 그들이 추적하고 있는 각 Spout에 대한 책임을 어떤 Spout 태스크가 지고 있는지 어떻게 추적하느냐이다. Spout 태스크가 새로운 튜플을 내보낼때 이는 간단하게 적절한 acker 에게 해당 Spout 튜플에 대한 책임을 지고 있는 태스크의 ID를 말해주도록 메세지를 보낸다. 그 후 acker가 트리가 완료된 것을 보면 어느 태스크 ID가 완료 메세지를 보냈는지 알 수 있다.
acker 태스크들은 튜플들의 트리를 추적하지 않는다. 수만 노드이상의 큰 튜플 트리에 대해 모든 튜플 트리를 추적하는 것은 acker에 의해 사용되는 메모리양이 너무 커질 수 있다. 대신 acker들은 Spout 튜플당 고정된 공간만 요구하는 전략을 갖고 있다. 이 추적 알고리즘은 스톰 동작의 핵심이며 획기적인 것 방법 중에 하나이다.
acker 태스크는 Spout 튜플 ID와 값들을 맵으로 저장한다. 첫번째 값은 후에 완료 메세지를 보내기 위해 사용되는 Spout 튜플을 생성한 Spout 튜플 태스크 ID이다. 두번째 값은 64비트 숫자이다. 일명 "ack val"이라고 불리움. ack val은 전체 튜플 트리의 상태를 표현하고 있고 얼마나 크던 작던 상관없다. 트리에서 ack되거나 생성된 모든 튜플의 id를 xor 한 값이다.
acker 태스크가 ack val 값이 0이 되는것을 알아차렸을 때 튜플 트리가 완료된 것을 의미한다. 튜플 ID는 64비트 랜덤 숫자 이기 때문에, "ack val"이 우연히 0이되는 것은 극히 드물다. 만약에 수학으로 보면 초당 10K ack가 일어나는 상황이면 이는 우연히 0이 발생하는 상황은 50,000,000 년정도 걸릴것이다. 아뭏턴 토폴로지에서 튜플이 실패했는데 데이터를 잃을 수 있는 경우는 이 경우 뿐이다.
지금까지 신뢰성 알고리즘을 이해했다면 실패의 경우를 겪어보고 스톰의 경우 어떻게 데이터 손실을 피하는지 알아보자.
- 태스크가 죽어서 튜플이 ack되지 않는다: 이 경우에 실패한 튜플을 위한 트리 최상위에 Spout 튜플 ID 타임아웃이 발생하고 리플레이될 것이다.
- acker 태스크가 죽는다: 이 경우에 acker 가 추적하고 있는 모든 Spout 튜플들은 타임아웃이 발생하고 리플레이 될것이다.
- Spout task 죽는다: 이 경우에 Spout와 통신하는 source는 메세지들을 리플레이해야 할 책임이 있다. 예를 들어, Kestrel 과 RabbitMQ 큐는 클라이언트가 연결이 끊어지면 큐에 메세지들이 돌려질 것이다.
Tuning reliability
Acker 태스크들은 가벼워서 토폴로지에서 많은 것들이 필요하지 않다. Storm UI를 통해 그들의 퍼포먼스를 살펴볼수 있다. (__acker) 만약에 제대로 성능이 나지 않는다면 더 많은 acker 태스크들이 필요할 것이다.
만약에 신뢰성이 그다지 중요하지 않는 경우라면, 다시말해 실패 상황에 대해 튜플들을 잃어버리는 것에 대해 별 신경을 쓰지 않는다면 Spout 튜플들에 대한 튜플 트리를 추적하지 않으므로 퍼포먼스를 향상시킬 수 있다. 튜플트리에 모든 튜플에 대한 ack 메세지가 있기 때문에 튜플 트리를 트랙킹하지 않으면 전달되는 메세지의 수를 절반으로 줄인다. 추가적으로 더 적은 다운스트림 튜플 ID를 유지해도 되고 네트워크 사용량도 줄인다.
신뢰성 기능을 제거하는 세가지 방법이 있다. 첫째 Config.TOPOLOGY_ACKERS 를 0으로 지정한다 . 이렇게 하면, 스톰은 spout에서 튜플을 내보낸 후 즉시 spout의 ack 메소드를 호출 할 것이다. 튜플트리는 추적되지 않을 것이다.
두 번째 방법은 메세지에 기반하여 메세지의 신뢰성을 제거하는 것이다. SpoutOutputCollector.emit 메소드에 메세지 ID내보내는 것으로 개별 Spout에 대한 추적을 끌수 있다.
마지막으로, 토폴로지에서 튜플 다운스트림의 일부 처리가 실패하는지에 대해 신경쓰지 않는다면, 그 튜플들을 내보낼 때 앵커되지 않는 튜플로 내보낼 수 있다. 어떤 Spout 튜플에도 앵커되지 않았기 때문에 ack되지 않아도 Spout 튜플들이 실패되지 않는다.